Le modèle que nous allons vous présenter ici est un Binary Deep Convenlutional Network : il s’agit donc d’un modèle de classification d’images automatisé. Pour le client Restofolio, l’objectif était de pouvoir distinguer les photos de plats cuisinés (n’importe quelles entrées, n’importe quels plats de résistance ou desserts) des autres photos postées (photos de la carte, de l’équipe, d’événements…) par les restaurateurs sur leur page Facebook.
Cet article fait suite à notre article de présentation des réseaux de neurones que nous vous conseillons fortement de lire avant celui-ci.
Warning: Undefined array key "image-max-width" in /home/imagile-production/www/releases/20260604083350/wp-content/plugins/imagile-flexible-content/components/images.php on line 178

L’installation de l’environnement nécessaire à l’entraînement d’un modèle est probablement une des étapes les plus compliquées. Après plusieurs essais et beaucoup de lecture, nous avons décidé d’utiliser un ensemble de librairies ce qui rend l’installation puis le développement plus simple.
Cet environnement fonctionne très bien sur Windows 10, Ubuntu 16.04 et Mac OS X. Enfin l’installation des « Cuda dev tools » ainsi que de cuDNN est nécessaire pour faire le calcul avec le GPU.

Tensorflow est le logiciel open source qui permet de développer, d’entraîner et d’utiliser un réseau de neurones assez simplement. Il a été rendu public par Google en novembre 2015 et est très probablement à l’origine de la démocratisation du deep learning.
« TensorFlowTM is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API. – Tensorflow »
Tensorflow propose deux langages de développement : le C++ ou le Python. Nous nous sommes naturellement orienté vers Python (3.5) que nous maîtrisions déjà et pour lequel plus d’exemples sont disponibles.
Dans une logique de développement modulaire et de simplification de la gestion des dépendances et des performances, nous avons choisi de rajouter une couche en développant notre modèle avec Keras.
Il permet de simplifier la gestion du GPU pour le calcul, mais également de développer des modèles facilement compatibles entre Tensorflow et Thenao (principal concurrent de Tensorflow).
« Keras is a high-level neural networks library, written in Python and capable of run- ning on top of either TensorFlow or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research. – Keras »
Nous avons enfin utilisé Anaconda afin de simplifier la gestion de notre environnement Python et un Jupyter Notebook afin de pouvoir visualiser nos courbes d’apprentissage en direct. Ces deux librairies ne sont pas directement liées à notre réseau, à vous d’utiliser ici les solutions qui vous semble les plus appropriées.

- L’entraînement d’un modèle peut être très long sans le matériel approprié. Je vous recommande fortement d’utiliser le calcul GPU. En effet, notre modèle s’entraînait en une vingtaine de minutes avec deux Nvidia GTX970 donc, en CPU, vous pouvez compter dix fois plus de temps.
- Les technologies que nous présentons ci-dessous utiliseront la totalité des ressources disponibles pendant l’apprentissage.
- La qualité de votre jeu de données et des réglages de votre modèle sera l’un des éléments clefsde son bon fonctionnement.
Cette étape est primordiale dans le bon fonctionnement d’un réseau de neurones. Si le jeu de données des deux classes n’est pas cohérent, le modèle ne sera pas pertinent.
Comme nous avons choisi un modèle binaire, nous avons deux classes à créer. Il est important que ces classes soient proportionnées et conséquentes si bien que nous nous sommes fixé sur 100 000 images par classe :
- Une classe « plat » : cette classe a pour objectif d’apprendre à notre modèle ce qu’est notre définition d’un plat. En l’occurrence, nous ne nous intéressons qu’à des plats cuisinés (entrées, plats de résistance ou desserts) et correctement présentés. L’absence de présence humaine sur la photo est également souhaitée. Nous avons donc choisi des photos d’un maximum de plats différents qui respectaient ces critères.

- Une classe « non-plat » : ici, il a été plus difficile de déterminer les critères de cette classe. Dans un premier temps, nous avons analysé les éléments redondants postés par les restaurateurs qui n’étaient pas des plats (ardoise, photos de soirées, de viande crue, de personnes, de flyers…). Dans un second temps, nous avons récupéré des images en fonction de leur complexité (la viande crue est plus compliquée à distinguer qu’une carte par exemple).

Une fois le jeu de données assemblé, il ne reste plus qu’à le préparer correctement pour que notre modèle puisse l’exploiter efficacement (la création d’un petit script Bash est ici une très bonne idée… !).
En effet, toutes les images devront être dans deux dossiers :
- Un dossier contenant les images d’entraînement et de validation (des deux classes, car, c’est votre data-set au complet).
- Un dossier contenant les images de test (des images différentes, mais il n’y a pas besoin d’en avoir beaucoup : une vingtaine dans notre cas).
Il est nécessaire d’adopter une convention de nommage pour pouvoir distinguer les deux classes (<classe>_<i> .jpg).
Avant de commencer à présenter les grandes étapes du développement (qui est assez minimaliste et tient en un seul fichier), il est nécessaire de vous introduire les grandes étapes de la vie d’un réseau de neurones avec Tensorflow :
- La phase d’apprentissage (Le training)
- La phase de validation
- La phase de prédiction
La phase de prédiction n’est possible que lorsque votre modèle sera entraîné : c’est en fait l’exploitation de votre réseau de neurones.
Dans un premier temps, le script importe les dépendances du modèle puis il va stocker la localisation des images en numpy array (tableau multidimensionnel) afin de pouvoir les apprendre au modèle. Ces images vont ensuite être redimensionnées (le modèle a besoin que toutes les images aient la même taille) et converties afin que le modèle puisse les comprendre. C’est ensuite que la logique binaire de notre modèle va opérer en assignant chaque image à sa classe respective.
Dans un second temps, on va passer à la définition de notre modèle. Ce dernier est composé de différentes couches. Dans le cas présent, le nôtre est une version réduite de l’architecture VGG16.
Nous avons utilisé quatre blocs convolutionnels ainsi qu’un « fully-connected » classifieur.Si l’on voulait expliquer cela rapidement, on pourrait dire que chaque couche convolutionelle n’a accès qu’aux couches inférieures : l’apprentissage du modèle passe donc par elles (on dit qu’elles sont connectées localement). La couche « fully-connected », elle, a accès à tout le modèle : c’est grâce à cette dernière que sont faites les prédictions après la période d’apprentissage. Enfin, il faut définir un optimisateur (RMSprop [lr=1e-4]) et un objectif (binary crossentropy) : nous avons choisi ceux préconisés pour les modèles de classification binaire.
Enfin, nous avons utilisé plusieurs callback très importantes pour visualiser les statistiques de notre modèle et pour effectuer certaines actions :
- La « cross validation » lors de l’apprentissage : à chaque nouvel epoch (un epoch correspond à un cycle complet d’apprentissage), le jeu d’apprentissage et le jeu de validation vont être modifiés de façon aléatoire.
- Une callback qui récupère les statistiques de notre modèle par epoch (accuracy et losses par exemple).
- Une callback d’early stopping si les losses (somme des carrés résiduels des erreurs du modèle) de validation ne diminuent plus.
- Une fonction permettant de conserver en mémoire le meilleur modèle sur un apprentissage complet.
Pour choisir le meilleur de nos modèles, nous avons retenu trois critères :
- L’analyse de l’accuracy/losses ;
- L’analyse des courbes ROC ;
- L’analyse des prédictions de test.
Il y a trois grandes raisons pour qu’un modèle ne soit pas pertinent :
- L’overfitting : le modèle connaît trop bien le jeu de données d’entraînement ce qui impacte son capacité à généraliser.
- L’underfitting : le modèle n’arrive pas à généraliser (entraînement, validation et prédiction).
- Le jeu de données n’est pas approprié ou comporte trop d’erreurs ce qui perturbe le modèle.
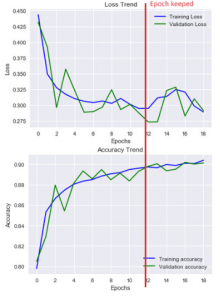
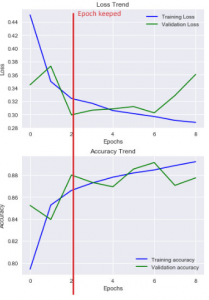
Pour interpréter ces résultats (attention aux échelles, elles sont dynamiques en fonction des valeurs), nous nous sommes basé sur ce modèle :
- Underfitting : le nombre d’erreurs de validation et d’apprentissage est élevé (losses élevées et accuracy basse).
- Overfitting : le nombre d’es erreurs de validation est élevé alors que celui des erreurs d’apprentissage est faible.
- Bon ajustement : le nombre d’erreurs de validation est faible, mais légèrement supérieur à celui des erreurs d’apprentissages.
- Ajustement inconnu : le nombre d’erreurs de validation est faible, mais celui des erreurs d’apprentissage est « élevé ».
Ici, le modèle A semble plus pertinent : il n’a pas connu de cas flagrant d’overfitting (léger pic pendant l’epoch 2 mais la différence n’est que de 0.035 environ) contrairement au modèle B. Ce dernier semble par ailleurs beaucoup plus instable.
La courbe ROC (Receiving Operating Characteristics) est une représentation graphique des performances d’un modèle. En ordonnée, on trouve la sensibilité (le taux de vrais positifs, c’est-à-dire le nombre de fois où le modèle a attribué la bonne catégorie une image) et en abscisse, l’inverse de la spécificité (1 — taux de faux positif).
Cette courbe est également un outil de choix pour ajuster la taille du batch (nombre de data apprise simultanément par le modèle) et le pourcentage du dataset utilisé pour la validation.
Il faut enfin noter que si un modèle est mauvais (il établit de mauvaises prédictions), mais qu’il a malgré tout une courbe ROC excellente, cela signifie que son code est bon, mais que le jeu de données de l’une ou des deux classes n’est pas adapté.
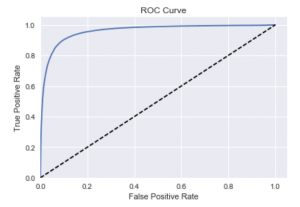
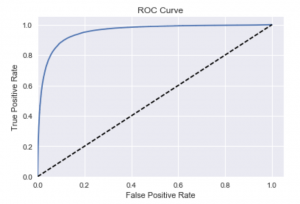
L’analyse générale d’une courbe ROC est aisée. En effet, plus l’aire sous la courbe (AUC : area under the curve) est grande, plus le modèle est performant :
- Un modèle totalement aléatoire aura une courbe correspondant à la diagonale en pointillés. Si vous avez une telle courbe, alors votre modèle est inutile : il choisira la bonne classe dans 50 % des cas ce qui revient à baser vos prédictions sur un random.
- Le modèle idéal, lui, n’aura que trois points distincts : (0, 0), (0, 1) et (1, 1). Le but est donc d’avoir une courbe s’en approchant le plus possible.
L’analyse détaillée, quant à elle, va dépendre de votre besoin. Selon ce besoin, vous pourrez adapter la taille des données de validation afin de diminuer le taux de faux positifs (plus de précision) ou à l’inverse augmenter le taux de vrais positifs (plus d’accuracy).
Dans notre cas, on constate au premier coup d’œil que ces deux modèles ont de très bonnes courbes ROC. Attention, le choix d’un modèle ne peut pas se faire qu’à partir de la seule analyse d’une courbe ROC, mais doit être couplé avec l’analyse de prédiction. Le modèle peut être performant, mais ne pas avoir « compris » votre besoin, ce qui est généralement causé par un dataset non adapté.
En regardant de façon plus précise, on peut constater que le modèle A est légèrement plus fiable alors que le modèle B, lui, est un peu plus performant. C’est parfaitement normal et attendu, car la quantité de données de validation est plus importante pour le modèle A que pour le modèle B.
Concrètement, qu’est-ce nous appelons performance et précision ? Ces termes correspondent respectivement à « accuracy » et à « precision » en anglais. La nuance est subtile :
- Quand on cherche à augmenter l’accuracy (la performance), on essaie de diminuer le taux de faux négatif : plus de données seront retenues, mais le taux de faux positifs sera plus élevé.
- Quand on cherche à augmenter la precision (la précision), on essaie de diminuer le taux de faux positifs : les données retenues seront plus fiables, mais moins nombreuses.
Cette phase d’analyse est de loin la plus simple et la plus importante. Dans le code de notre modèle, on lui indique un dossier contenant des images de test (essayez ici de choisir des images simples et d’autres plus complexes afin de voir comment le modèle réagit). La phase de test fonctionne exactement de la même façon que la phase de prédiction à la différence près qu’elle est automatisée à la fin de l’entraînement de chaque modèle.


| Modèle | Item 1 | Item 2 | Item 3 | Item 4 | Item 5 | Item 6 | Item 7 | Item 8 |
|---|---|---|---|---|---|---|---|---|
| A | -99.92% | -99.94% | 90.12% | -68.02% | 87.32% | 57.96% | 99.48% | 96.58% |
| B | 81.84% | -99.91% | 99.41% | 98.77% | 97.96% | 92.77% | 99.89% | 99.69% |
Les valeurs négatives correspondent ici au taux de confiance du modèle pour la classe « non-plat », tandis que les valeurs positives correspondent au même taux pour la classe « plat ». Un modèle qui ne ferait pas d’erreur aurait donc quatre taux négatifs puis 4 taux positifs.
Il est intéressant de constater que le modèle A a des seuils de confiances plus variables que le modèle B : c’est qu’on avait déduit sur les courbes ROC précédemment !
Ainsi, le modèle A semble être le plus pertinent : il est d’ailleurs le seul modèle parmi tous nos essais (une vingtaine) à avoir choisi la bonne classe pour la pièce de viande brute. De plus, ses seuils de confiances affichés sont cohérents avec la difficulté de classification des images données.
Le modèle B, lui, est en fait catastrophique : il classifie presque toujours une image en plat avec des taux de confiance aberrant. C’est le bon exemple pour montrer la pertinence de l’analyse des prédictions de test. En effet, là où tout semblait le caractériser comme performant, on se rend compte qu’il n’est pas utilisable.
Si vous souhaitez tester notre modèle ou avoir une base de développement pour vous essayer à la création du vôtre, nous vous invitons à vous rendre sur le repository github de ce projet qui est public. Vous y retrouverez la procédure d’installation du modèle préentraîné, la procédure d’installation pour entraîner un nouveau modèle (attention, nous ne fournissons pas le jeu de données pour des raisons de droits et de poids) et un rapport de projet détaillé.
Nous espérons que vous vous amuserez autant que nous dans cet univers où tout semble possible !


